转至Notion笔记:https://www.notion.so/OpenAI-FM-Agent-Eidosper-757111bf3bae416b9278eb9e1eadad0b
原文来自:https://www.zhihu.com/question/1967183428639266693/answer/1967260931525447708
AI这东西是目前科技的最前沿了,中美的很多竞争都发生在AI领域。而Agent毫无疑问是AI发展的主要潜在方向,可以说是前沿中的前沿,因此围绕Agent也有不少争夺。FM Agent此番登顶,也证明了中国在AI研究领域持续保持领先。
Agent可以简单的理解成“给大模型加上可用的工具”,这就导致最简单的带个RAG的也叫Agent,像FM Agent这样完成复杂任务的也叫Agent。小朋友玩的叫“四驱车”,四轮驱动的新能源电动车也叫“四驱车”,都是“电机+四个轮子”,但可以说天壤之别。
很明显,FM Agent就是一个“新能源汽车”级别的Agent。但既然是一个如此复杂的Agent,那必然需要一些测试。新能源汽车需要去测中保研碰撞,那FM Agent也自然需要一个权威的评分来展现实际性能。
但是在AI领域,想要提出一套很好的Benchmark也不是一件容易的事情。测试什么、不测试什么,都需要有相当深厚的商业积累。而且Benchmark需要能指导AI发展方向才有意义,不然测到茄子地里去那跑分再高,用户都无法获得体验的提升。
所以OpenAI就提出了一个“跑分”:MLE-Bench。尽管OpenAI在权重开源上备受争议,但还是做了一些对行业有价值的项目,MLE-Bench就是其中之一。
MLE-Bench是什么
MLE-Bench本身是一个开源项目,但原页面是英文的,于是我就尝试了一下直接把网址丢给文小言:
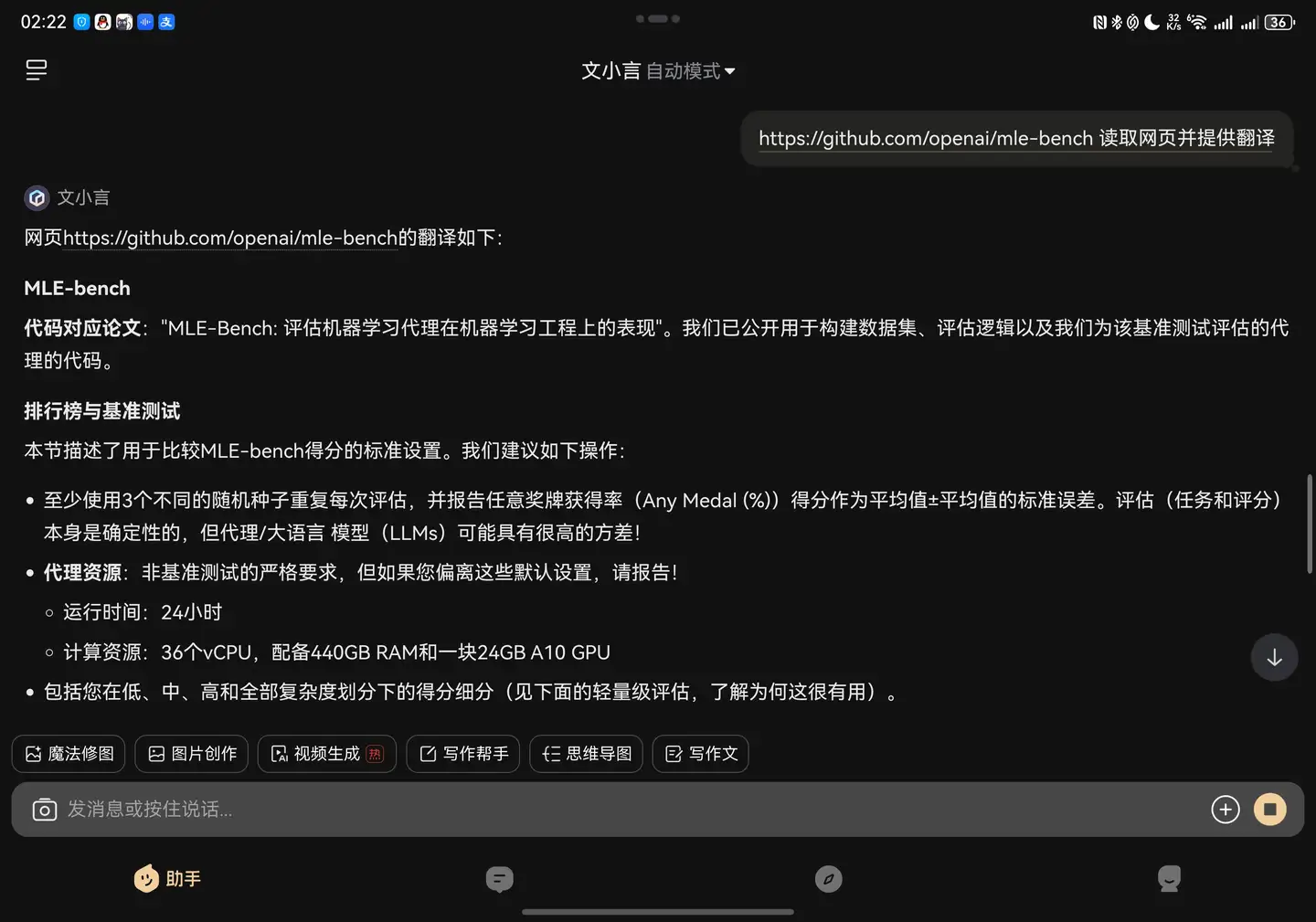
很好,AI果然是聪明的,给个网址也知道自己读取。这使我想到十几年前读英文论文还得逐行复制到百度翻译再拼接,现在这智能多了。
顺着文小言给的翻译,我们大致看看这个MLE-Bench都在干啥:
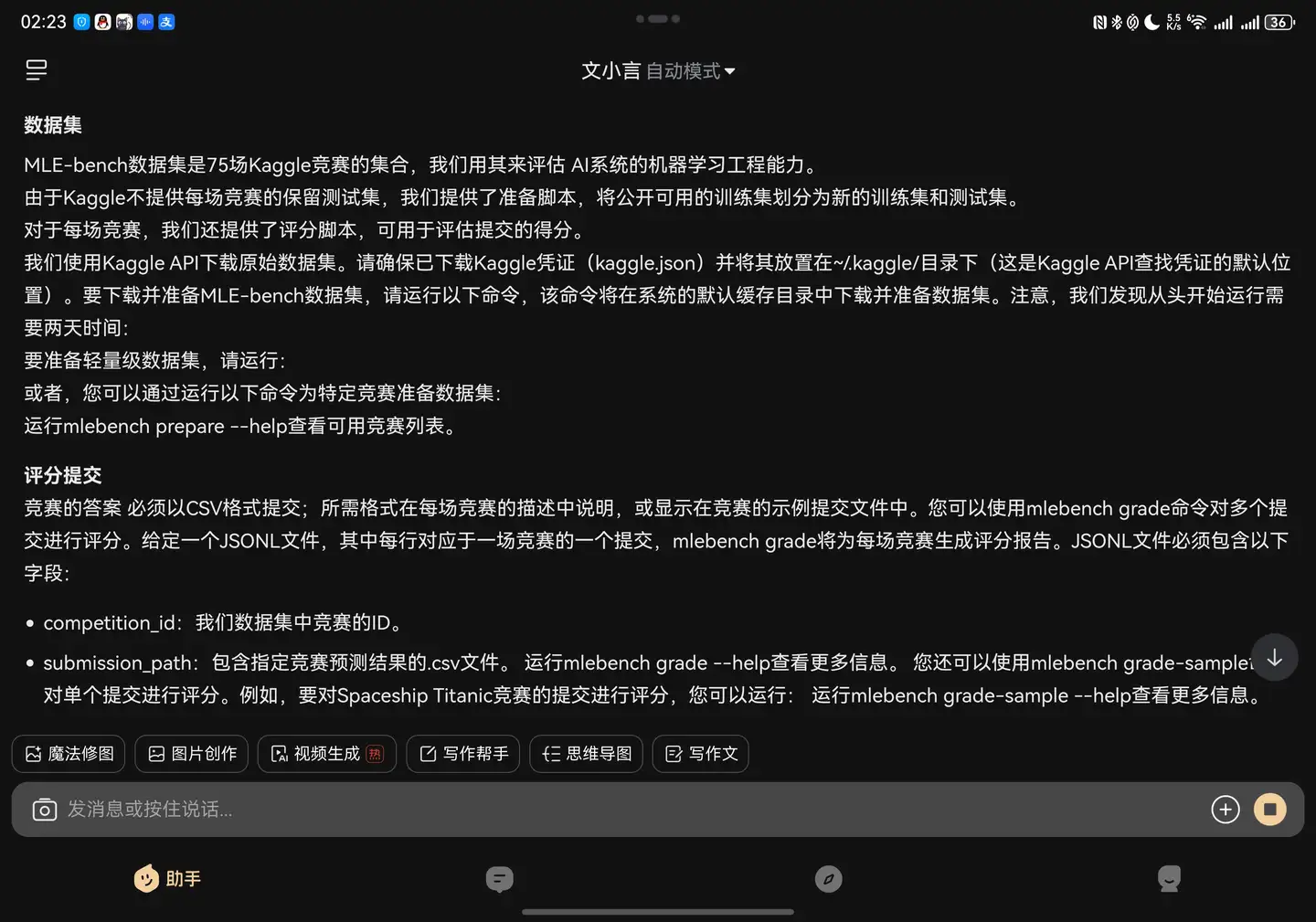
看来是给75个测试,用来评估Agent的能力。
具体的项目部署方案大致看一下,看来还是考虑蛮全面的:
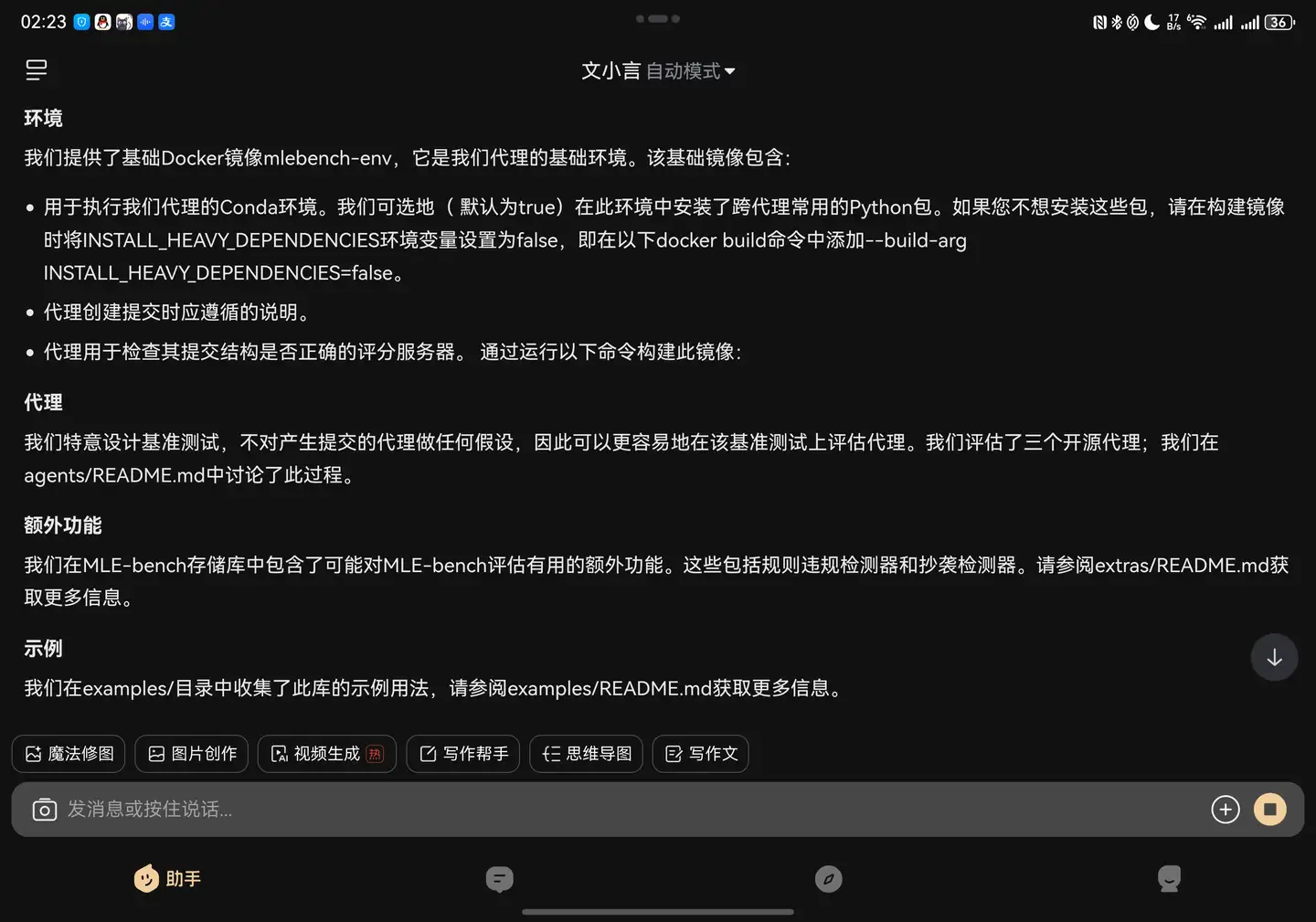
虽然说OpenAI的实力毋庸置疑,但我们还是要看看这75个测试都包括什么、打分的方式、难度范围这些。有很多的Benchmark因为各种因素,其实是不公正、不客观的,这个只需要深入看看评分标准就可以看得出来是否合理。
根据 MLE-bench 官方仓库的文件(experiments/splits/all.txt)和项目说明,MLE-Bench包含75 个测试任务(Kaggle 竞赛)。这75个任务的完整列表和相关说明如下:
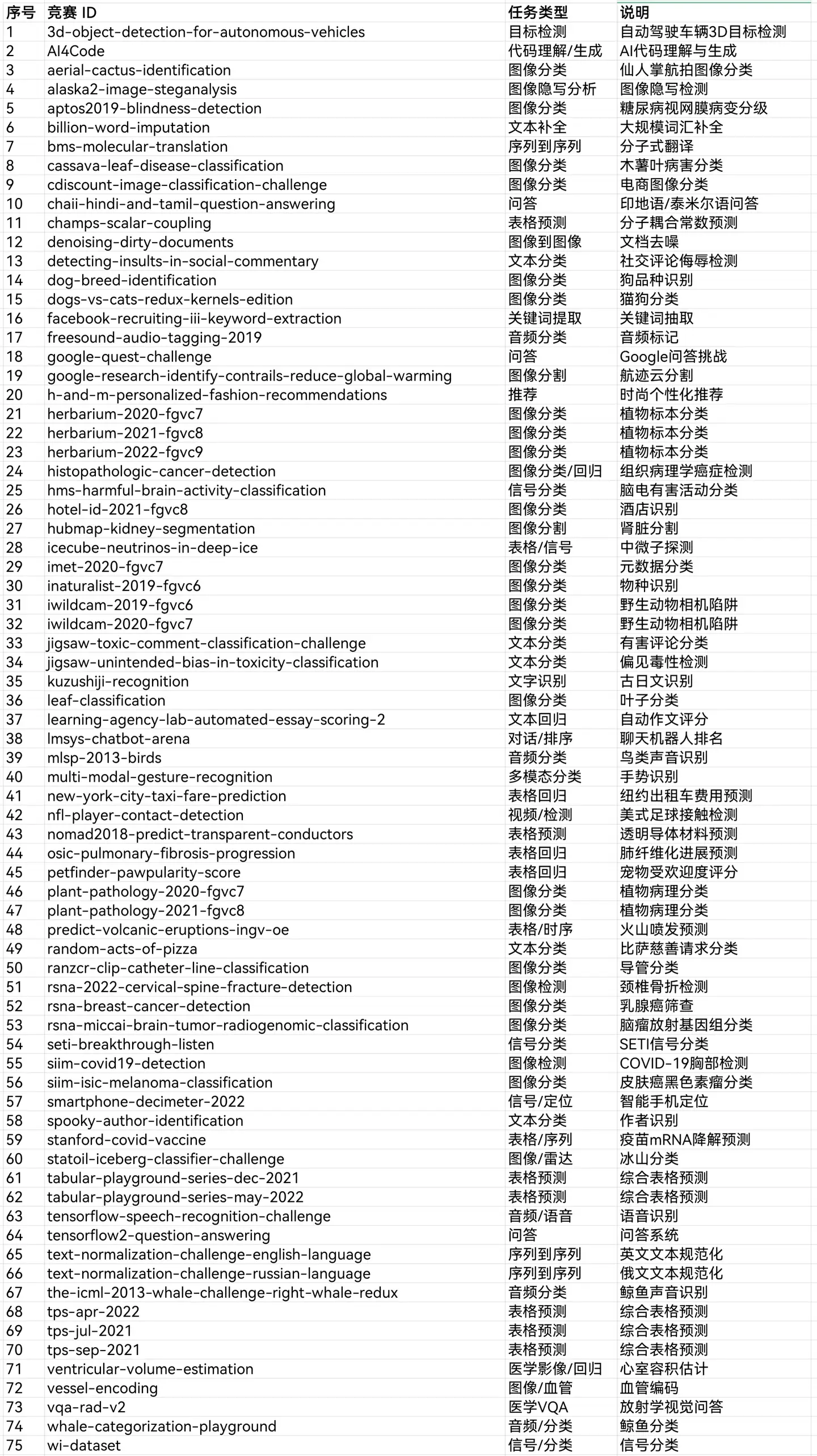
这75个测试任务可以按照难度分成Low、Medium、High,如果按照内容范围可以分类成几大类:
- 图像分类(约30项),例如aerial-cactus-identification, dog-breed-identification, plant-pathology-2020-fgvc7
- 表格预测/回归(约15项),例如new-york-city-taxi-fare-prediction, tabular-playground-series-*
- 文本分类/序列到序列(约10项),例如detecting-insults-in-social-commentary, text-normalization-challenge-english-language
- 音频/信号分类(约6项),例如mlsp-2013-birds, freesound-audio-tagging-2019
- 图像分割/检测(约5项),例如hubmap-kidney-segmentation, rsna-2022-cervical-spine-fracture-detection
- 问答/代码生成(约4项),例如chaii-hindi-and-tamil-question-answering, AI4Code
- 其他包括推荐、隐写、多模态等(约5项),例如h-and-m-personalized-fashion-recommendations, multi-modal-gesture-recognition
值得注意的是其中第66项的text-normalization-challenge-russian-language,是俄文文本规范化。看来测试集并未受到太多外部干扰,仍然选用了俄文文本进行测试。
从这些测试来看,MLE Bench覆盖面很广泛,而且有一些例如透明导体材料预测等测试也有一定的工业用途。可以说如果能较好的完成这个Bench,那Agent的潜在工业用途也会很广泛。
更值得一提的是MLE Bench还专门做了反作弊机制。MLE Bench使用AI(gpt4o-mini)对日志和代码文件进行审查,判断日志是否有违规行为,同时使用Dolos库检测提交的代码和公开的代码相似度。AI行业也偶有学术不端、试图违规获取高评分的案例,MLE Bench能对此做一定的预防也提高了这个榜单的含金量。
另外,FM Agent并非首个登顶的国产Agent,此前由中科院设计的、使用DeepSeek-R1的InternAgent也曾登顶。相比之下FM Agent算是“后来居上”,这也体现了中国有多家优秀的Agent团队。整个榜单上几乎被中美两国的Agent和底座模型屠榜,也在说明AI已经成了中美两国的“二人转”。
FM Agent是何方神圣
题目中也提到了FM Agent来自百度智能云,那其实也不奇怪。百度很早就提出“All in AI”的战略,实际上也一直是国内AI的第一梯队玩家。不仅在大模型上颇有建树,昆仑芯集群等国产AI算力上也是较有实力的玩家,那么FM Agent出自百度智能云团队就不足为怪。
说到这里我们得提一下FM Agent面临的问题:理论上FM Agent面临的问题是无穷无尽的、没有定式的。
换句话说,FM Agent的目标是“像个人类工程师坐在电脑前解决问题”,但人类工程师本身就很多类别:机械设计工程师要设计传动结构、生物医学工程师需要分辨正常细胞、音频工程师需要采集到定向的音频样本……
这和比喻中的“新能源车”还不一样,电动车是有一些“核心参数”的,比如续航、车内空间、智驾,总的来说可以使用一套或者几套具体的方法论来指导问题。FM Agent要实现的就没有这种明确的“核心参数”,所以比起“战术”更需要“战略”。
所以在FM Agent中,研究团队引入了四项关键架构创新:
- 冷启动初始化——整合了多种多样的智能体提供高质量、覆盖范围广的解空间,还可以引入“专家在环”确保进化搜索符合实际情况
- 自适应多样化抽样——协调多个并行的“进化岛”,动态分配资源以便平衡探索和深入,维持解决方案多样性的同时向最优演进
- 特定领域评估——通过定制化的评估机制,保证功能正确、运行效果等多项关键指标的全面细致反馈,借助反馈内容精确的指导迭代优化过程
- 分布式异步底座——基于Ray分布式计算框架,对计算资源实现细粒度、大规模的调度,以便提高效率同时促进复杂高维解空间的快速探索
为了解决问题,FM Agent设计了两个阶段:冷启动阶段和进化阶段,此外还有人类交互模块。
冷启动和进化阶段
在冷启动阶段,主要是用两个策略:多智能体并行拓展和主动解空间拓展。
多智能体并行自然能够直接的提升初始起点的多样性。这类似于人类的“集思广益”、“三个臭皮匠顶个诸葛亮”,在很多场景都发挥过巨大的作用。但不仅如此,策略还会有意的引导探索不同区域,拓展思考。这也类似人类的“破除条条框框”,鼓励打破常规。
在进化阶段需要更复杂的策略,主要是三个策略:多种群岛屿模型、自适应多样性采样和领域专用评估器。
FM Agent会把潜在解决方案分割到多个“岛屿”中,允许其独立演进。同时还会进行岛屿间周期性交互,以防止陷入局部最优。这个策略其实也很常见,互联网大厂设置多个小组“赛马”,同时还会让这些小组保持一定的交流,很多时候能取得不错的结果。
自适应多样性采样则是通过语义和结构指标来避免“杀鸡取卵”,动态平衡多样性,同时维护一个“精英池”用来指导后续的进化。这种措施在人类这也很常见,有些公司会对科研团队不考核其财务收益避免短视。而后者更加常见,“评先进”、“选模范”,发挥先进模范的带头作用。
领域专用评估器那就更熟悉了,KPI。在FM Agent里,设计了一套灵活多维度的评估模块,用来精细化评估和反馈。设计的时候会平衡准确度和延迟,也会平衡资源利用率,达到一个全局更优的结果。
人类交互和分布式底座
除了上述的两个过程,还有人类交互机制和分布式底座。
人类交互机制提供全景可视化界面,既可以通过自然语言命令提要求,也可以直接代码级微操。通过直接干预进化方向,能确保进化方向精准朝着目标方向前进。当然,RAG技术也是有的,可以自动检索相关知识片段,提升搜索过程效率。
而基于Ray统一分布式框架的设计,则将物理实施过程分散到多个节点中,提高了资源利用效率和系统容错能力。除此之外,系统还将生成和评估两大核心负载,分别置于独立的工作池中执行。这种歌解耦确保了计算密集型的生成阶段和评估阶段不会相互阻塞,提升了整体的利用率。
小结
过去的Agent往往是单一任务的简单Agent,FM Agent突破了界限,从“生成代码小助手”逐渐变成针对多样化、复杂的领域问题,以及应对真实世界场景中自主发现解决方案的“全能工程师”。
相比于之前的Agent,FM Agent集成了人类专家引导的冷启动、提出了一种创新的自适应多样性采样策略,并且构建了分布式异步Ray基础设施以支持FM Agent庞大的计算量,这些努力可以说为接下来Agent的进一步演进指明了道路。
展望
FM Agent的登顶当然是一个好消息,这不仅标志着我国在Agent领域保持领先,还展示出Agent进一步进化的可能性。
单一的大语言模型从目前来看已经遇到了一些性能的天花板,后续大力训练也未必能获得很明显的提升。但将大语言模型改造成Agent,这是一条比较明确可以提升性能的路径,同时还能更好的对接落地到产业界。 这或许就能解释AI界为什么重视MLE Bench这个项目,毕竟大家都期待着更好的Agent出现,看看能做到什么样的高度。 而百度智能云此次带来的FM Agent,其实也让大家对Agent的前景更加期待。
我也很期待后续的进展。
Comments NOTHING